An analysis may require the ability to generate correlated random samples. For example, imagine we have monthly returns for three financial indicators over a 20 year period. We are interested in modeling these returns using parametric distributions for some downstream analysis, perhaps to estimate tail behavior over a large number of samples. In this post, I’ll demonstrate that assuming independence of truly correlated random variables falls short, and how to correctly model the correlation for sample generation. The financial indicator data is available here.
import matplotlib as mplimport matplotlib.pyplot as pltimport numpy as npfrom scipy import statsimport pandas as pdindicator_url ="https://gist.githubusercontent.com/jtrive84/9955433e344ec773e5766657f961fde5/raw/b2e2c99db1e05aeb69186550b9c78cc9412df911/sample_returns.csv"df = pd.read_csv(indicator_url)df.head()
date
us_credit
us_market
global_market
0
1/31/2001
0.035525
0.0301
0.022123
1
2/28/2001
-0.001583
-0.0950
-0.091336
2
3/31/2001
0.002638
-0.0675
-0.075002
3
4/30/2001
0.010607
0.0738
0.075063
4
5/31/2001
0.010448
0.0035
-0.010473
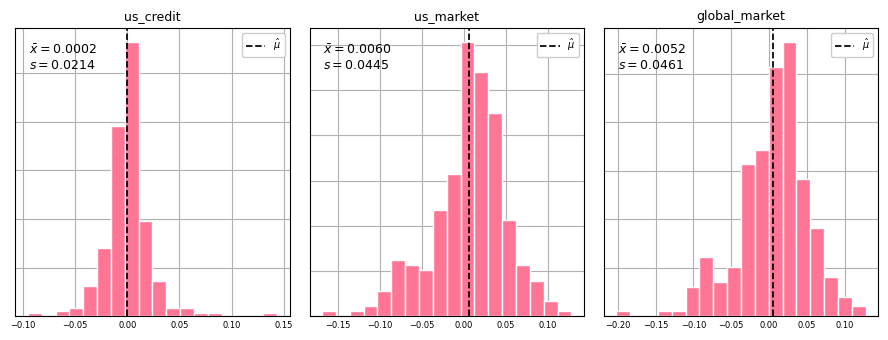
The table contains monthly returns for us_credit, us_market and global_market from 2001-01-31 up to 2023-06-30, but our approach can be extended to any number of financial indicators. Our goal is to find an appropriate parametric distribution for each indicator to use for sample generation. We start by plotting histograms of each indicator to get an idea of the distributional form (symmetric, skewed, etc.). This will dictate which distribution we use to find the best fitting parameters via maximum likelihood. Since there are positive and negative values for each indicator, using a normal distribution is probably a safe bet. If values of the indicators were strictly positive, we would use a distribution with support on \((0, \infty)\) such as gamma, lognormal or weibull.
The distribution of each indicator appears relatively normal. Given that the parametric form has been identified, we can use Scipy to determine the optimal parameters to fit three separate normal distributions (one per indicator) via maximum likelihood.
from scipy.stats import norm# Get normal parameter estimates (mean & standard deviation) via maximum likelihood.mu0, std0 = norm.fit(df["us_credit"], method="MLE")mu1, std1 = norm.fit(df["us_market"], method="MLE")mu2, std2 = norm.fit(df["global_market"], method="MLE")dparams = {"us_credit": {"mean": mu0, "std": std0},"us_market": {"mean": mu1, "std": std1},"global_market": {"mean": mu2, "std": std2}, }print(f"\n- us_credit : mean={mu0:,.5f} std=={std0:,.5f}")print(f"- us_market : mean={mu1:,.5f} std=={std1:,.5f}")print(f"- global_market: mean={mu2:,.5f} std=={std2:,.5f}\n")
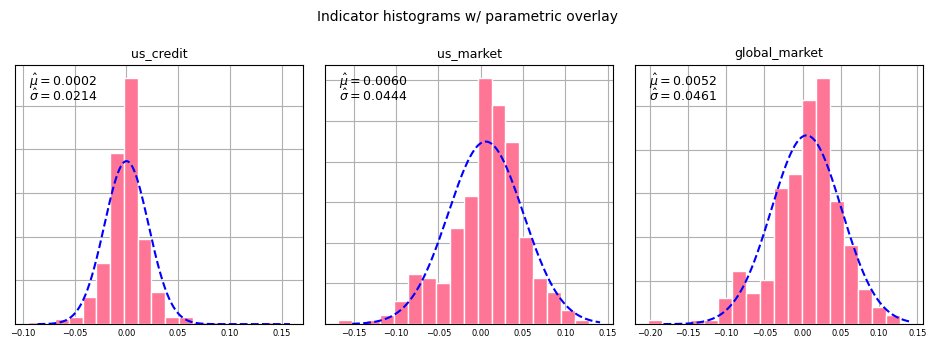
The parameter estimates match very closely with the empirical mean and standard deviation overlaid on each histogram. This is because the MLE estimates for the normal distribution are equal to the sample mean and the unadjusted sample variance. Next we overlay the best fitting parametric distribution with each indicator histogram in order to assess the quality of fit.
The distributions in each case enclose the original histograms pretty well, with decent tail coverage in each instance. To demonstrate the approach, we next generate independent random samples from each indicator.
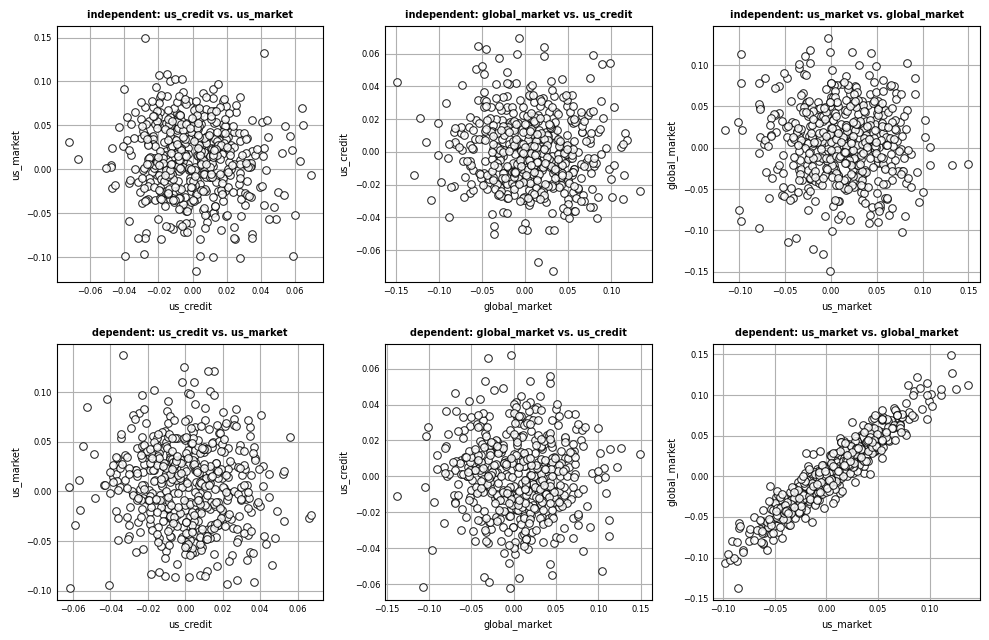
Here we assume the value that an indicator takes on is independent of all other indicators. This is almost surely not the case. Let’s check how correlated the 3 selected indicators are within the original sample:
df.corr()
us_credit
us_market
global_market
us_credit
1.000000
-0.099877
-0.037652
us_market
-0.099877
1.000000
0.955514
global_market
-0.037652
0.955514
1.000000
Do the independent samples exhibit the same correlation?
dfsims1.corr()
us_credit
us_market
global_market
us_credit
1.000000
-0.072533
-0.066023
us_market
-0.072533
1.000000
-0.044359
global_market
-0.066023
-0.044359
1.000000
Not surprisingly, us_market and global_market are over 95% correlated in the original data. This is not exhibited within the set of non-correlated samples. With such high correlation, it is not reasonable to assume independence across indicators. We need instead to find a way to generate correlated random samples. This can be accomplished using Numpy’s multivariate normal distribution.
As a brief aside, the significance of a correlation between two random variables depends on the sample size. To test if the correlation between two variables demonstrates a linear relationship at the 5% significance level, we compute:
\[
|\rho| \gt 2 / \sqrt{n},
\]
In our case, there are 270 samples, therefore \(n = \sqrt{270} \approx 16.4\). Thus, in order for the correlation between two indicators to be significant at the 5% level, it needs to be greater than \(2 / 16.4 \approx .12\), which is clearly the case for global_market-us_market.
# Generate correlated random samples.# Specify number of simulations to generate.nbr_sims =500# Create vector of means.means = [mean0, mean1, mean2]# Bind reference to covariance matrix.V = df.cov().valuesdfsims2 = pd.DataFrame( np.random.multivariate_normal(means, V, nbr_sims), columns=indicators )dfsims2.describe()
us_credit
us_market
global_market
count
500.000000
500.000000
500.000000
mean
0.000547
0.005966
0.005387
std
0.021886
0.042421
0.044833
min
-0.062250
-0.097373
-0.137454
25%
-0.013780
-0.024495
-0.027463
50%
0.000788
0.007268
0.006098
75%
0.015203
0.033833
0.035412
max
0.067324
0.136830
0.148773
The min and max values for each indicator seem to align with what was observed in the original data. Let’s verify that the samples in dfsims2 are correlated.
dfsims2.corr()
us_credit
us_market
global_market
us_credit
1.000000
-0.084854
-0.038219
us_market
-0.084854
1.000000
0.944791
global_market
-0.038219
0.944791
1.000000
This matches closely with the original correlation profile. Let’s visualize the correlation in the generated random samples by comparing indicator samples from the independent simulated dataset vs. the dependent simulated dataset.